Week 2 Reflection — Creating and Hosting a Website
In this week’s workshop, I learned how to create and host a simple website. I began by activating my Leeds New Media hosting account and connecting it through cPanel and FileZilla. Understanding how to use the public_html folder helped me realise the importance of structure and organisation in web hosting. I created a basic HTML homepage that included my personal introduction and information about my studies. Adding a title, headings, and paragraphs allowed me to understand the foundational structure of a webpage.
I also learned how to link an external CSS file to add simple styles. Although the workshop focused on basic skills, it helped me become more confident in publishing my work online. This process gave me a clearer view of how digital content is created, uploaded, and made publicly accessible. I now understand that even a simple webpage represents the intersection of creativity, technical knowledge, and accessibility.
Week 3 Reflection — Connecting to Hosting Account and Web Scraping
This week’s session deepened my understanding of website hosting and introduced the concept of web scraping as a method of digital research. I first learned how to connect to my web hosting account correctly using cPanel and FTP clients such as FileZilla. The troubleshooting process—testing different networks, browsers, and passwords—helped me understand the technical dependencies behind online publishing. Uploading files to the public_html folder and checking whether the index.html appeared correctly made me realise how even minor errors in setup can affect the accessibility of a digital artefact.
The second part of the session introduced web scraping, which shifted my focus from creating content to analysing it. By using the WebScraper.io browser extension, I explored how to extract structured data from web pages, such as text, links, or images. This practice allowed me to see websites not only as designed interfaces but also as data-rich environments that can be studied for research purposes. I was particularly intrigued by how scraping transforms visible content into datasets that can answer research questions in media studies.
Overall, this week connected technical literacy with analytical thinking. Managing hosting accounts improved my understanding of the digital infrastructure, while web scraping encouraged me to think critically about data ethics, access, and the hidden structures of online information.
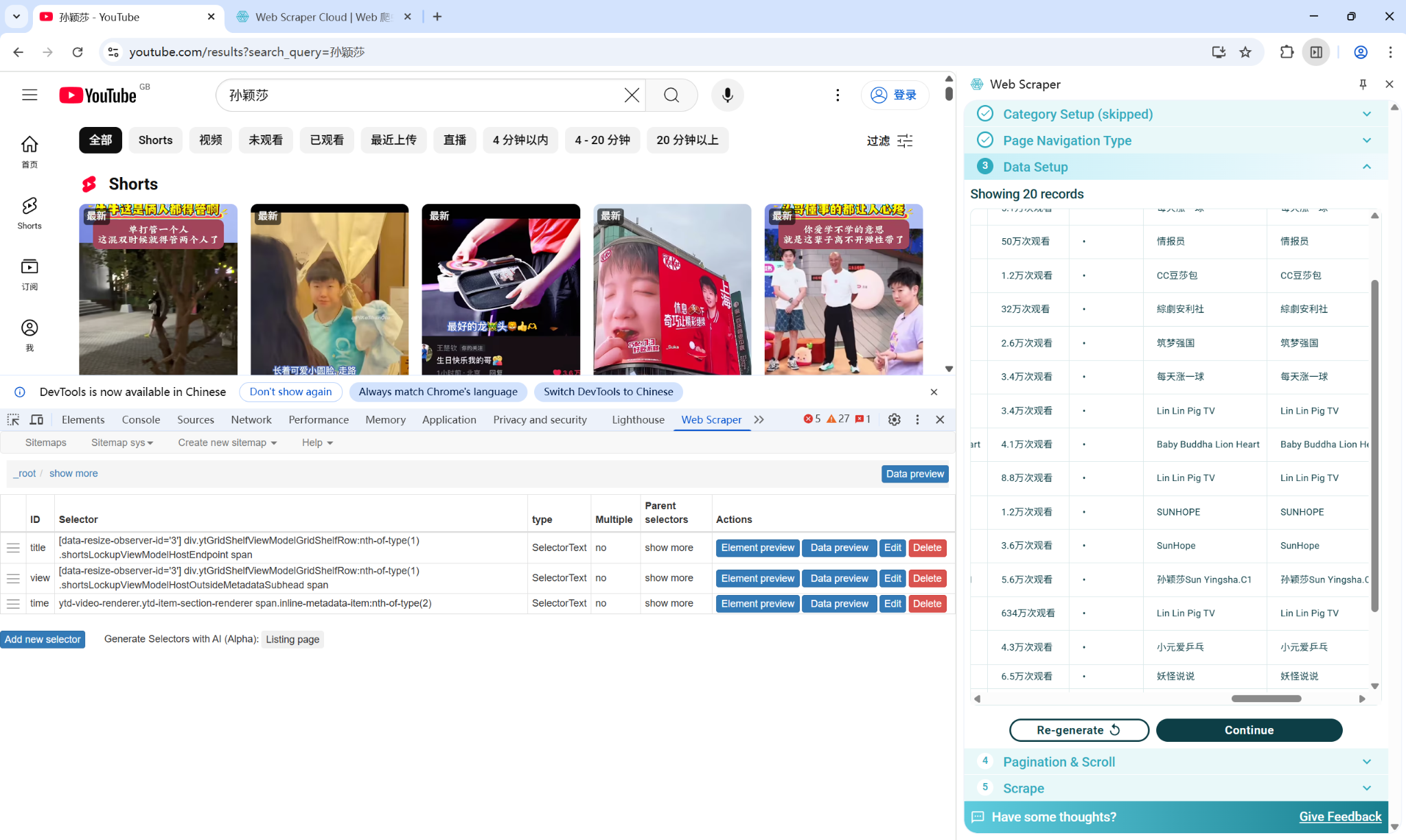
My Data Collection Practice
The following screenshot shows my practice of data collection using WebScraper.io:
Week 4 Reflection — Data, Power, and Classification
This week’s topic helped me reflect on how data is not neutral but deeply shaped by systems of power and hierarchy.
From Crawford’s Atlas of AI, I learned that the ways data is captured and classified are never objective—they
reflect the assumptions, interests, and worldviews of those who create them. Similarly, D’Ignazio and Klein’s idea
that “what gets counted counts” reminded me that exclusion can happen invisibly when certain groups or perspectives
are not represented in datasets.
Thinking about my own experiences using social media platforms like TikTok, I realized how much personal data I
constantly consent to share—such as my viewing habits, likes, and engagement time. Yet, I rarely know how these data
points are used. Algorithms classify and predict my preferences, reinforcing certain types of content while ignoring
others. This makes me more aware of how classification systems in digital media both shape my online experience and
subtly influence my worldview.
During the workshop, when designing a survey about students’ use of generative AI, I found it challenging to decide
what data to collect without reproducing biases. For example, asking only about productivity or convenience could
ignore ethical concerns or emotional impacts. This made me realize that ethical and inclusive data collection requires
questioning not just how we collect data, but why we collect it—and who might be excluded by our
design choices.
Overall, this week deepened my understanding of data as a political and cultural construct. It encouraged me to think
critically about my own role as both a data subject and a potential data collector in digital media research.
Week 5 Reflection — Data Visualisation
This week’s workshop deepened my understanding of data visualisation as a way to tell stories and communicate ideas through design.
Rather than simply displaying numbers, visualisation is about creating meaning — it invites the audience to see relationships,
patterns, and arguments that might otherwise remain hidden.
In class, we discussed how the same data can be visualised in different ways depending on the message we want to convey.
Through this discussion, I realised that every visualisation carries intention. For example, when we were asked to imagine presenting
our data to potential investors or funding partners, we needed to decide what kinds of visual connections would be most persuasive.
I learned that visualisation is not just technical, but strategic — it involves thinking about audience, purpose, and emotion.
During the activity, I was encouraged to think critically about how design choices (such as chart type, layout, or colour) can shape interpretation.
Good data visualisation doesn’t just show information — it frames a narrative. I also learned the importance of considering what should be emphasised
or left for the audience to discover on their own.
Overall, this week helped me see data visualisation as a creative process that combines analysis, storytelling, and ethics.
It reminded me that visualising data means constructing a point of view, and that design decisions are as influential as the data itself in shaping understanding.
Week 6 Reflection — Algorithmic Identity and Data
This week’s session explored how algorithms shape our online identities and influence the way we are seen, categorised, and targeted on digital platforms.
Algorithmic identity is a dynamic construct produced from our interactions — what we like, share, watch, and how long we linger on posts.
Algorithms do not simply reflect who we are; they actively participate in creating who we appear to be.
In our group discussion we focused on three core issues: privacy,identity, and bias.
First, privacy: platforms like TikTok rely on intensive data collection to predict and influence user behaviour.
This form of surveillance capitalism (Zuboff, 2019) reduces users’ control over their own data and digital selves.
Second, identity: the platform incentivises users to perform in ways that increase algorithmic visibility.
Over time, repeated exposure to similar content can fix users into particular identity labels (e.g. “beauty creator”, “funny guy”, “anime fan”),
which may in turn influence self-perception and practice on the platform.
Third, bias and discrimination: algorithms trained on historical data often reproduce existing social inequalities.
Some groups (such as gender or ethnic minorities, or low-income communities) may be less likely to be recommended or may be suppressed
by moderation mechanisms. These dynamics show that algorithmic systems can inadvertently silence or marginalise certain voices.
These reflections made clear that algorithms are not neutral tools but cultural and political agents that shape power relations in digital media.
As both data sources and data subjects, users’ online experiences are continuously filtered, classified, and monetised — raising important ethical
and political questions about control, representation, and accountability.
Week 7 Reflection — Identities and Generative AI
This week's workshop helped me reflect more deeply on how generative AI shapes, simplifies, or misrepresents identity.
We focused on negative prompting, which means telling the model what not to do. When I experimented
with this, I realised that the AI often added emotions, confidence, or narrative patterns that did not match my real experiences.
Using negative prompts helped me pull the output closer to my own voice.
This made me more aware that generative AI does not simply “mirror” identity. Instead, it creates a version of me based on patterns
learned from large datasets. As Munster notes, machine learning systems produce outputs shaped by probabilities, aesthetics, and
previous examples — not by personal intention. This means the AI version of “me” is partly constructed by the system’s assumptions.
The workshop also connected to our earlier discussions about algorithmic identity. When I compared my own negative
prompting results with how platforms categorise users, I noticed a similar pattern: both systems build identities from limited signals.
For example, if the AI picks up one academic phrase, it exaggerates it; if a platform detects certain behaviours, it forms a fixed
category. In both cases, the identity produced is simplified, and sometimes inaccurate.
Reflecting on this helped me understand how generative AI might shape people’s self-perception. When an AI repeatedly outputs a version
of “me” that is more confident, emotional, or polished, it could subtly influence how I think about my own voice. The process also made
me more aware of the importance of questioning how digital systems interpret, reduce, or reframe identity.
Overall, the workshop encouraged me to think more critically about the gap between who we are and how machine learning systems —
through prompts, patterns, and probabilities — construct us. It reinforced the idea that AI outputs are not neutral reflections but
narrative constructions shaped by training data and design choices.
Week 8 Reflection — Digital Ecologies in Practice
In this workshop I explored digital ecologies through a sensory mapping exercise at Kirkgate Market.
The activity asked us to use sight, sound, smell, touch and bodily feelings (e.g. hunger, cold) to sense the market
and then translate those experiences into digital forms using photos, audio and notes.
The market felt like a dense human–food ecology: ingredients came from many places, but the labour, transport
and non-human processes behind them were mostly invisible. This absence made me think about who and what is
marginalised in food systems, and how digital mediation often highlights products while obscuring broader
ecological and labour relations.
Market stall — variety of goods and visual textures.Artist installation — jars and audio devices used for speculative listening.Fish on ice — texture and temperature conveyed visually.
Translating sensory experience into digital media was challenging. I used photos, short audio clips and quick
notes to suggest smell, temperature and texture. For example, images of fish on ice and jars of spices helped
evoke cold or scent indirectly, while recordings of sizzling or ambient market noise suggested atmosphere.
This showed me that digital tools do not simply record; they shape how experiences are perceived and shared.
The workshop encouraged a more-than-human perspective: food appears not only as commodity but as the outcome of
entangled practices involving humans, non-humans, technology and environment. Constructing a sensory map revealed
both the limits of digital representation and creative ways to make hidden relations more visible.
Week 9 Reflection — Creative Hacking, Sensing, and the Body
In this workshop I learned the basics of creative hacking with Arduino by building a simple temperature sensor circuit.
The task made abstract topics—analogue input, digital output, PWM—concrete: temperature was converted to a voltage,
read as a numeric value by the board (0–1023) and then displayed through the serial monitor and LED feedback.
Working hands-on emphasised that bodily data is mediated. The sensor does not give “temperature” directly; it produces
a voltage that we calibrate, interpret and visualise. Small wiring mistakes or baseline settings produced different readings,
which highlighted the labour and judgement behind apparently objective data.
Arduino setup: breadboard, TMP sensor and LEDs.
The activity also showed how failure can be informative: debugging wiring and adjusting baselines taught me about
calibration, thresholds and the assumptions embedded in sensors and code. These practical problems connect to the
module’s critical themes — data about bodies is constructed through hardware, code and interpretive choices, not simply
“read off” nature.
Overall, the workshop reframed sensing as an embodied, experimental practice. Creative hacking made visible the
assemblage of body + sensor + code + interpretation, and encouraged a critical stance toward how bodily data is produced
and used.